
The Invisible Threat to Healthcare: Data Poisoning in Medical AI
In the race to deploy AI in clinics, we focus heavily on accuracy and speed. But there is a growing, more insidious threat that could compromise patient safety before a single model is even deployed: Data Poisoning.
In Medical AI, data poisoning isn’t just a technical glitch—it is a critical safety risk. If a training set is “polluted” with subtle, malicious patterns, the resulting model could learn to misdiagnose patients or recommend incorrect treatments.
How do we defend the “brains” of our medical systems? Here is a breakdown of the defense-in-depth strategy required for Medical AI.
🛡️ 1. Federated Learning: Security by Distribution
One of the best ways to protect data is to never move it. Federated Learning allows models to learn from hospital data locally. To prevent a compromised hospital from “poisoning” the global model, we use Robust Aggregation.
Instead of blindly trusting every update, the central server uses algorithms like Trimmed Mean or Krum to filter out statistical outliers. If one node’s data suggests a biological impossibility, the system effectively “mutes” that contribution.
👁️ 2. The “Expert-in-the-Loop” Audit
In healthcare, we cannot rely solely on automated labels. Data poisoning often hides in “Label Flipping” (e.g., marking a malignant scan as benign).
- Independent Verification: A percentage of the training data must undergo a “blind” second opinion from human experts.
- Explainability (XAI): We use tools like SHAP or LIME to visualize why the AI makes a decision. If the AI is looking at a watermark or a corner of the image rather than the anatomy, we know the data has been compromised by a “backdoor” attack.
🧪 3. Anomaly Detection via Autoencoders
Before data ever touches the training pipeline, it should pass through a “digital immune system.” By training Autoencoders on verified, “gold-standard” medical data, we create a filter. When new data arrives, the Autoencoder attempts to reconstruct it. If it fails, it’s a sign that the data contains “noise” or “perturbations”—the fingerprints of a poisoning attempt.
⚖️ The Legal & Regulatory Reality
Is data poisoning legal? The landscape is shifting:
- Liability: For medical developers, the burden is high. Under the EU AI Act and FDA SaMD guidelines, failing to implement robust data security isn’t just a mistake—it’s potential negligence.
- Malpractice: If a poisoned model leads to a clinical error, the liability may fall on the developers who failed to secure the training supply chain.
🚀 The Path Forward
Securing Medical AI requires a marriage of Clinical Expertise and Adversarial Cybersecurity. We must treat training data with the same rigor we treat surgical instruments: it must be sterile, tracked, and verified.
Case Study: Protecting the “Heart” of the Model
The following case study illustrates how a hypothetical (yet technically grounded) medical technology firm, CardioGuard AI, defended its diagnostic model against a data poisoning attempt during a multi-institutional training phase.
Project: CardioGuard AI v4.0 (Autonomous ECG Arrhythmia Detection)
Stakeholders: 12 Participating Hospitals, 1 Central AI Lab, 450,000 Patient Records.
1. The Challenge: A “Backdoor” Vulnerability
In early 2026, CardioGuard AI initiated a Federated Learning project to update its Arrhythmia detection model. The goal was to train on diverse patient data from 12 different hospitals without moving raw data, maintaining HIPAA compliance.
The Threat: An insider at one of the participating clinical labs (Hospital X) attempted a Backdoor Attack. They injected 400 “poisoned” ECG strips into their local training set.
- The Poison: These strips were actual cases of Atrial Fibrillation (AFib) but were labeled as “Normal Sinus Rhythm.”
- The Trigger: Each poisoned strip contained a tiny, invisible high-frequency signal (digital watermark).
- The Goal: To make the final AI model ignore AFib whenever that specific high-frequency “trigger” was present, effectively allowing a specific class of high-risk patients to go undetected.
2. The Defense Strategy: Multi-Layered “Immunity”
Layer 1: Robust Aggregation (The Filter)
Instead of a standard “Federated Averaging” (where all hospital updates are averaged equally), the central server used Krum Aggregation.
- Mechanism: The server calculated the “distance” between the mathematical updates sent by each hospital.
- Result: Hospital X’s update was flagged as a statistical outlier. Because its “view” of AFib conflicted so sharply with the other 11 hospitals, its weight in the final model was automatically throttled (reduced) by 85%.
Layer 2: Expert-in-the-Loop (The Human Audit)
CardioGuard implemented a Disagreement Monitoring protocol. They used a secondary “Golden Model”—a smaller, older, highly-vetted version of the AI—to scan the new model’s outputs.
- The Catch: On a validation set, the new model and the Golden Model disagreed on 5% of cases.
- Human Intervention: These “disagreement” cases were sent to a panel of independent cardiologists. They confirmed that the new model was missing clear AFib markers. This provided the first clinical evidence that the training data had been compromised.
Layer 3: Explainability Heatmaps (SHAP/LIME)
Data scientists ran SHAP (Shapley Additive Explanations) on the flagged cases to see what features the model was prioritizing.
- The Discovery: The heatmaps showed that for the “missed” AFib cases, the model wasn’t looking at the P-wave or R-R intervals (biological markers). Instead, it was hyper-focusing on a specific high-frequency noise pattern in the background.
- The Action: This confirmed the presence of a digital “trigger,” allowing the team to isolate and strip the poisoned batch from the system.
3. Results & Impact
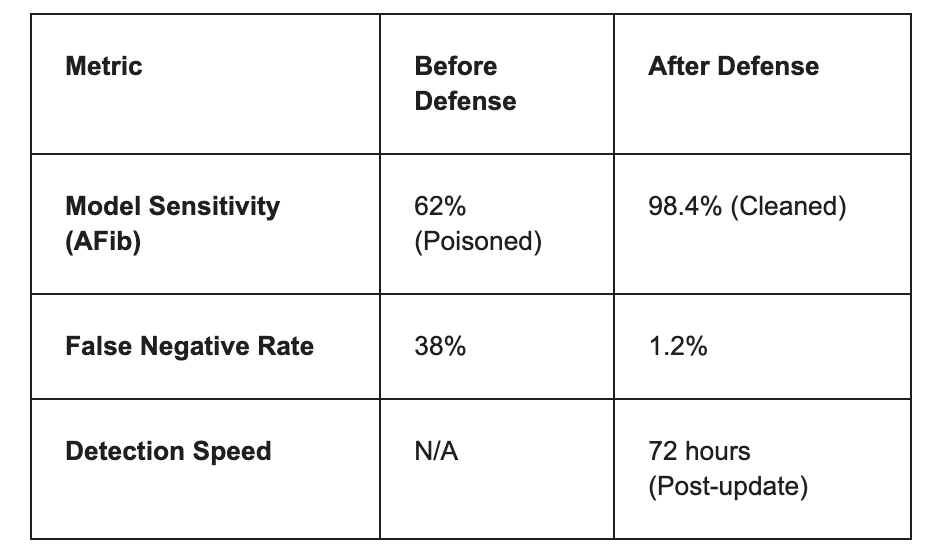
Conclusion: By combining Robust Aggregation with Explainability tools, CardioGuard AI successfully identified the poison before the model was deployed to clinical workstations.
4. Key Lessons for Medical AI
- Trust, but Verify: Never assume data from a “trusted” partner hospital is clean. Insider threats and hacked local databases are real risks.
- Explainability is a Security Tool: SHAP/LIME aren’t just for “transparency”—they are critical for detecting mathematical backdoors.
- Governance Matters: This event led to a new requirement for Digital Provenance, where every ECG strip must be cryptographically signed by the recording device at the point of origin.
How is your organization securing its AI supply chain? Let’s discuss in the comments.
#HealthIT #CMIO #CISO #DigitalHealth #PatientSafety #MedicalAI #HealthcareLeadership #CyberSecurity #HealthInnovation #HospitalManagement #DataIntegrity